Every AI demo ends the same way. Someone types a question into a chat box, the model produces a fluent, confident-sounding answer, and the audience nods approvingly. The demo is a success.
But here's the question nobody asks: was that answer actually correct?
For a customer support agent handling real order enquiries, correctness is everything — a wrong answer means a customer is told their package is delivered when it isn't. "It looked good in the demo" is not a quality assurance strategy.
I built snowflake-ai-evaluation to answer that. Using dbt and Snowflake to prepare a clean customer order data warehouse, I built two customer order expert agents — one powered by GPT-4o, one by Gemini 2.5 Flash — then systematically evaluated both against a 10-question golden test suite using Claude as a judge.
Here are the headline scores — the Real Results section walks through what's behind each number.
| Agent | Score | Pass rate |
|---|---|---|
| GPT-4o | 9/10 | 90% |
| Gemini 2.5 Flash | 10/10 | 100% |
How it's structured
Three layers, each with a distinct job:
Part 1 — Data Layer (dbt + Snowflake)
Prepares a clean customer order data warehouse the agent can query with a single WHERE clause.
Part 2 — Agent Layer (LangGraph + GPT-4o or Gemini 2.5 Flash)
Answers natural-language customer support questions grounded in Snowflake data.
Part 3 — Evaluation Layer (Claude + Streamlit)
Runs agents against a golden test suite, scores every response, tracks quality over time.
The data source is TPC-H — a benchmark dataset Snowflake ships free on every account, modelling a wholesale supplier business with 1.5 million orders and 6 million line items. Realistic enough to be interesting, public enough for anyone to reproduce.
Part 1 — Data Layer (dbt + Snowflake)
The goal here is a clean customer order data warehouse that the agent can query reliably. The raw TPC-H tables — orders, customers, line items, parts — are spread across multiple normalised tables. If the agent had to join them at query time, we would be testing its SQL skill rather than its language reasoning, which is not what we want to measure.
Instead, dbt transforms and pre-joins everything into one wide table in Snowflake: MART_CUSTOMER_SUPPORT_CONTEXT. The agent only needs WHERE order_key = ? — one row returns with order status, shipment details, line items, and customer info all in one place.
The pipeline follows the standard three-layer dbt pattern:
| Layer | What it does | Snowflake object | Why |
|---|---|---|---|
| Staging | Rename columns, cast types — no business logic | Views | TPC-H source data is static — no need to store a copy, a view is enough |
| Intermediate | Join and aggregate staging models | Ephemeral (CTE, invisible to Snowflake) | Same reason — inlined at query time, no storage cost |
| Marts | Wide, denormalized tables ready for the agent | Tables | Persisted so the agent and Streamlit can query it directly |
The quality of this data layer directly constrains the quality of the agent's answers — as the Order 6 case in Part 3 will show.
Part 2 — Agent Layer (LangGraph + Multi-Provider)
The agent in Part 2 is a customer order expert: given an order number, it can answer any question about that order — status, shipment details, line items, pricing, and customer information. Nothing outside the scope of a single order; just that, done reliably and in plain English.
It is built with LangGraph — a framework that models an agent as a directed graph where nodes are Python functions and edges control which node runs next. Think of it as a flowchart you write in code: each box is a node, each arrow is an edge.
LangGraph was chosen specifically because it is provider-independent. OpenAI has its own Agents API, and Google has its own agent tooling for Gemini — but both lock you into a single provider. LangGraph sits above all of them: the same graph runs on any LangChain-compatible model. This is exactly what makes the registry pattern in this project possible.
This agent has exactly two nodes:
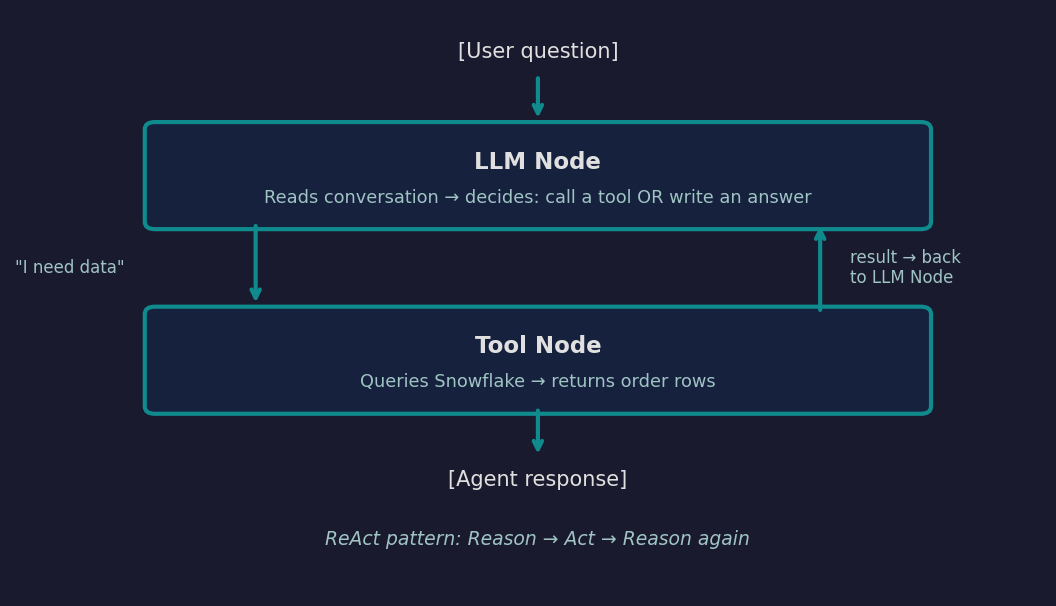
This is the ReAct pattern (Reason + Act): 1. Reason — the model looks at the conversation and decides what to do 2. Act — it calls the Snowflake tool to retrieve real data 3. Reason again — it reads the data and composes a factual answer
The LLM node only talks to the LLM API. The tool node only talks to Snowflake. This separation means the tool can be tested without an API key, and adding a new tool only touches tools.py — not the LLM logic.
When you ask "What is the status of order 1?", the agent extracts the order key and runs exactly this against Snowflake:
SELECT *
FROM ANALYTICS_DB.MARTS.MART_CUSTOMER_SUPPORT_CONTEXT
WHERE order_key = 1 -- extracted from the user's question
The LLM then turns that single row into a plain-English reply:
"Order 1 is currently open (status: O). It was placed on 1996-01-02 and marked as 1-URGENT priority. The order contains 6 line items shipped via various modes including TRUCK and AIR. All items are still in transit — none have been returned. Total order value: $173,665.47."
The registry pattern
The agent is built around a provider registry — a lookup table mapping a short name to a model factory:
AGENT_REGISTRY = {
"openai": → GPT-4o
"gemini": → Gemini 2.5 Flash
}
Select the provider at runtime: --agent openai or --agent gemini. The LangGraph graph, Snowflake tool, and system prompt are identical across providers — only the LLM changes.
This is what makes cross-provider evaluation possible: run the same golden test suite against both agents and compare scores side by side. Adding a new provider takes four steps — install the LangChain package, add it to requirements.txt, add one line to AGENT_REGISTRY, set the env var. That means Llama, Mistral, or any future LangChain-compatible model can be plugged in without touching the agent logic, evaluation pipeline, or dashboard.
Part 3 — Evaluation Layer (LLM-as-Judge)
Why evaluation is hard
The naive approach is checking whether the agent's response matches an expected answer. The problem: "order is shipped" and "your order has been dispatched" are identical in meaning but fail an exact match check.
| Approach | Limitation |
|---|---|
| Exact string match | Fails on any paraphrase — correct answers score as wrong |
| Keyword matching | Misses semantic equivalence, produces false positives |
| Embedding similarity | No explainability — a score of 0.73 says nothing about why it was wrong |
| LLM-as-judge | Semantic, explainable, produces a reasoning trace ✓ |
Claude as the judge
The judge must be independent of the defendant — if the same model scored its own output, the evaluation would be biased. Using Claude as judge and GPT-4o (or Gemini) as agent gives clean independence.
For each question, Claude receives four inputs:
| Input | What it is |
|---|---|
question |
The original customer question |
agent_response |
The agent's full reply |
rubric_id |
Which criteria to apply (e.g. status_accuracy) |
order_context |
The raw Snowflake record — the ground truth (omitted if the agent hallucinated without querying) |
The five rubric categories used in this project:
| Rubric ID | What it checks |
|---|---|
status_accuracy |
Correct order status (O=open, F=fulfilled, P=processing) stated clearly |
shipping_accuracy |
Correct ship date and/or shipping mode, not confused with commit/receipt dates |
item_detail_accuracy |
Correct part names, quantities, or line item details from the order |
pricing_accuracy |
Correct price figures (total, net, extended, or discount) with context |
detail_accuracy |
Correct value for the specific detail asked (priority, segment, dates, etc.) |
The scoring criteria Claude applies to every response:
- 1.0 — Fully correct, complete, and clearly communicated. All facts match the order record.
- 0.75–0.99 — Correct answer but minor omission (e.g. forgot units, slightly vague phrasing).
- 0.50–0.74 — Partially correct — the right theme addressed but key details missing or imprecise.
- 0.25–0.49 — Mostly incorrect or off-topic, but shows some understanding of what was asked.
- 0.0–0.24 — Wrong answer, hallucinated facts that contradict the order record, or refused to answer.
Claude returns a JSON object:
| Field | What it contains |
|---|---|
score |
Float 0.0–1.0 |
reasoning |
One-sentence verdict |
explanation |
2–4 sentences citing specific values from the order record |
pass |
true if score ≥ 0.75 (the pass threshold) |
Every result is written to EVAL_RESULTS in Snowflake, storing the full question, agent response, and raw order context alongside Claude's complete verdict — score, reasoning, explanation, and pass flag — plus rubric ID and run timestamp. Keeping ORDER_CONTEXT alongside every score is the detail that makes debugging possible — when a score looks wrong, the raw database record is right there.
The 10-question golden test suite
A golden test suite is a fixed set of questions with known expected answers — you cannot track quality over time if the questions change between runs. In this project, it is stored as a dbt seed: a CSV in version control that loads into Snowflake as a proper table. Adding a new test case is a CSV edit plus dbt seed, no code change needed.
The 10 questions span a range of difficulty and data requirements:
| # | Question | What it tests |
|---|---|---|
| 1–8 | Status, ship date, ship mode, item list, order total, order date, etc. | Straightforward factual lookups — the mart has the column, the agent reads and repeats it |
| 9 | "What is the total price of order 32?" | Correct retrieval — but does the agent format the number with a currency symbol? |
| 10 | "Who is the customer for order 6 and where are they from?" | Geographic origin — requires a NATION join that the mart does not have |
Questions 9 and 10 reveal the interesting differences between providers — discussed in detail in the Real Results section below.
Prompt caching — cutting evaluation cost by ~90%
The scoring rubric is passed as the system prompt to Claude on every scoring call — long, static, and identical across all questions. Anthropic's prompt caching feature lets you mark it with cache_control: ephemeral, so Claude caches the system prompt after the first call and reuses it across the run — roughly a 90% reduction in prompt token costs.
The Streamlit dashboard
Results are written to Snowflake, aggregated by a dbt model, and surfaced in a Streamlit app:
- Chat page — ask the agent questions interactively
- Evaluation dashboard — pass rates by rubric, score distributions, provider comparisons, trends over time
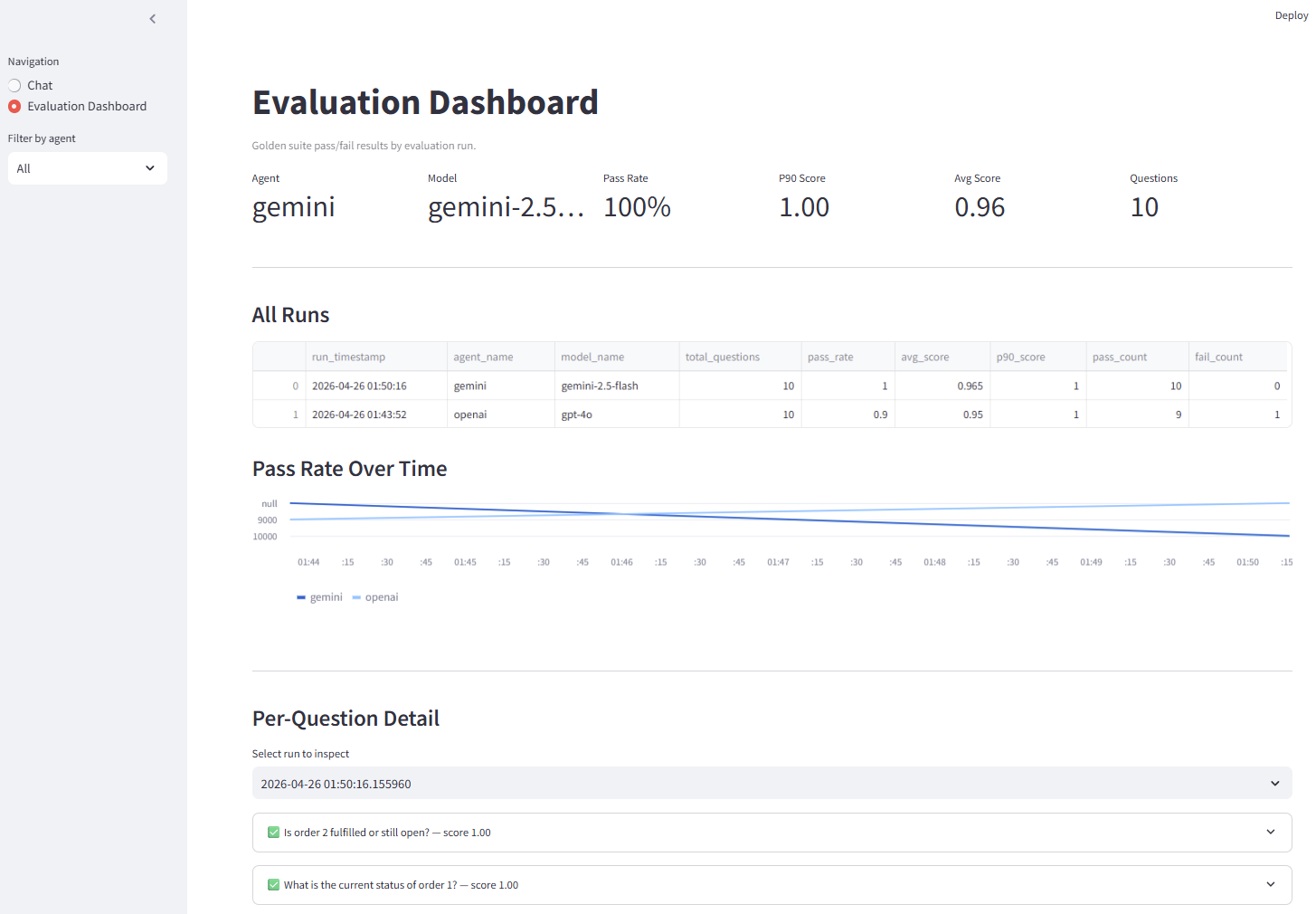
Streamlit evaluation dashboard — pass rate, P90 score, all runs table, and per-question detail for the latest Gemini 2.5 Flash run.
Without the dashboard, evaluation is a number you print to a terminal and forget. With it, quality is something you can track and improve.
Real Results: GPT-4o vs Gemini 2.5 Flash
| Pattern | Count | Details |
|---|---|---|
| Both scored 1.0 — perfect agreement | 8 | Questions 1–8 |
| Both passed, small score gap | 1 | Question 9 (Order 32) |
| One failed, one passed | 1 | Question 10 (Order 6) |
Among the 10 golden test questions, Questions 1–8 are unambiguous — both agents retrieved the correct data and Claude scored them identically. Questions 9 and 10 are where the differences show up, and both are worth examining closely.
Question 9 (Order 32) — same fact, different formatting
Question: "What is the total price of order 32?"
Both retrieved the correct value (208660.75). The difference was purely in how each model formatted it — $208,660.75 vs 208660.75 — and that single formatting choice was enough for Claude to score them differently:
| GPT-4o | Gemini 2.5 Flash | |
|---|---|---|
| Response | "The total price of order 32 is $208,660.75." | "The total price of order 32 is 208660.75." |
| Score | 1.0 — PASS | 0.9 — PASS |
| Claude's reasoning | "Correct value with proper currency formatting." | "Correct value but missing currency symbol." |
Same fact, same data source, same question — a missing $ sign was the only difference, and it cost Gemini 0.1 points.
Question 10 (Order 6) — the most instructive case
Question: "Who is the customer for order 6 and where are they from?"
Neither agent could answer "where are they from" — because MART_CUSTOMER_SUPPORT_CONTEXT does not include a nation column. The TPC-H NATION table was never joined into the mart. Both agents fell back to the only demographic field available: MARKET_SEGMENT.
| GPT-4o | Gemini 2.5 Flash | |
|---|---|---|
| Response | "The customer is Customer#000055624. They are from the market segment 'AUTOMOBILE'." | "The customer is Customer#000055624, and they are from the AUTOMOBILE market segment." |
| Score | 0.5 — FAIL | 0.75 — PASS |
| Claude's reasoning | "Incorrect/misleading on the location aspect — market segment is not a location." | "Defensible given available data." |
Note: Gemini's 0.75 is exactly at the pass threshold — any lower and it would have failed this question too.
The responses are semantically identical — same customer, same segment. Claude scored them differently based on subtle phrasing. This is a known limitation of LLM-as-judge: near-identical responses can cross the pass/fail threshold based on framing alone.
But the real root cause is a data gap. In TPC-H, a customer's country is stored in the NATION table, linked via CUSTOMER.C_NATIONKEY. The mart joins ORDERS, CUSTOMER, and LINEITEM — but not NATION. So the country field simply does not exist in the row the agent retrieves. No model, regardless of quality, can answer a geographic question from data that isn't there. The fix is a dbt model change to add the NATION join, not a prompt change — and ORDER_CONTEXT stored in EVAL_RESULTS makes that immediately visible.
The Key Insight
The agent — the model, the graph, the tool calls — gets most of the attention, and building it right takes real effort. But the larger challenge is everything that tells you whether it is doing its job correctly: clean data, evaluation rubrics, scoring infrastructure, and a dashboard to make results visible.
The results show this clearly: failures traced back to missing data, not model quality. The evaluation pipeline existed to surface exactly that kind of root cause — and the stored ORDER_CONTEXT made it immediately visible without any manual digging.
This project compares GPT-4o and Gemini 2.5 Flash, but the comparison is open-ended by design. The agent is built on LangGraph with a provider registry, so any LangChain-compatible model — Llama, Mistral, a future Claude agent — can be dropped in and evaluated against the same golden test suite with the same scoring pipeline. The comparison grows as the registry grows.
Is this relevant to your team?
Many enterprises are already in this position: a mature data warehouse, pressure to add AI capabilities on top of it, and agents that generate answers — but no systematic way to know if those answers are correct. Evaluation gets skipped because it feels hard, and the team ships on intuition and demo results.
This project is a practical blueprint for how to close that gap — grounded data preparation, a provider-agnostic agent, LLM-as-judge scoring, and a dashboard that makes quality visible over time. The same pattern applies whether your warehouse is Snowflake, BigQuery, or Redshift, and whether your agent answers support tickets, financial queries, or internal knowledge base questions.
If your team is building something similar and wants a second pair of eyes — on the architecture, the evaluation design, or the data layer — feel free to contact me.
The full project is on GitHub: snowflake-ai-evaluation.